Вещи, которые я хотел бы, чтобы больше разработчиков знали о базах данных

Вольный перевод статьи Things I Wished More Developers Knew About Databases
Подавляющее большинство компьютерных систем имеют определенное состояние и, скорее всего, зависят от системы хранения данных. Мои знания о базах данных накапливались со временем, но на этом пути наши ошибки проектирования приводили к потере данных и сбоям в работе. В системах с большим объемом данных базы данных составляют основу целей и компромиссов при проектировании систем. Несмотря на то, что игнорировать работу баз данных невозможно, проблемы, которые предвидят и испытывают разработчики приложений, часто оказываются лишь верхушкой айсберга. В этой серии статей я поделюсь несколькими мыслями, которые мне показались полезными для разработчиков, не специализирующихся в этой области.
- Вам повезло, если 99,999% времени сеть не является проблемой.
- ACID имеет много значений.
- Каждая база данных имеет различные возможности согласованности и изоляции.
- Оптимистическая блокировка - это вариант, когда вы не можете удержать блокировку.
- Существуют и другие аномалии, кроме грязных чтений и потери данных.
- Мы с моей базой данных не всегда соглашаемся по поводу упорядочивания.
- Шардинг на уровне приложения может жить вне приложения.
- AUTOINCREMENT'ing может быть вреден.
- Несвежие данные могут быть полезными и свободными от блокировок.
- Перекосы часов происходят между любыми источниками синхронизации.
- Латентность имеет много значений.
- Оценивайте требования к производительности в расчете на одну транзакцию.
- Вложенные транзакции могут быть вредны.
- Транзакции не должны поддерживать состояние приложения.
- Планировщики запросов могут многое рассказать о базах данных.
- Онлайновые миграции сложны, но возможны.
- Значительный рост базы данных вносит непредсказуемость.
Вам повезет, если 99,999% времени сеть не будет проблемой.
Вопрос о том, насколько надежны современные сети и как часто системы испытывают простои из-за сбоев в работе сети, является открытым. Имеющиеся исследования ограничены, и в них часто доминируют крупные организации, которые имеют специализированные сети с пользовательским оборудованием, а также специализированный персонал.
При 99,999% доступности сервисов Google ссылается на то, что только 7,6% проблем Spanner (глобально распределенной базы данных Google) вызваны сетевыми проблемами, хотя компания постоянно называет выделенную сеть основной причиной доступности. Исследование Бейлиса и Кингсбери, проведенное в 2014 году, опровергает одну из ложностей распределенных вычислений, сформулированную Питером Дойчем в 1994 году. Действительно ли сеть надежна?
У нас нет всестороннего исследования за пределами гигантов или через публичный Интернет. Также нет достаточных данных от крупных провайдеров о том, сколько проблем их клиентов можно отследить по проблемам с сетью. Мы часто сталкиваемся с перебоями в сетевом стеке крупных облачных провайдеров, которые могут вывести часть Интернета из строя на несколько часов, но это только те события, которые имеют большое влияние на большое количество видимых клиентов. Сетевые сбои могут затрагивать большее количество случаев, даже если не все события вызывают много шума. Облачные клиенты также не всегда имеют видимость своих проблем. При возникновении сбоя идентифицировать его как сетевую ошибку, вызванную провайдером, невозможно. Для них сторонние сервисы - это "черные ящики". Оценить последствия, не будучи крупным провайдером, невозможно.
По сравнению с тем, что крупные игроки сообщают о своих системах, можно с уверенностью сказать, что вам повезло, если сетевые проблемы составляют небольшой процент от потенциальных проблем, вызывающих перебои в работе. Сети по-прежнему страдают от обычных проблем, таких как аппаратные сбои, изменения топологии, изменения административной конфигурации и сбои питания. Но недавно я узнал, что недавно обнаруженные проблемы, такие как SHARK BITES (да, укусы акул), являются реальностью.
ACID имеет множество значений.
ACID означает атомарность, согласованность, изолированность, долговечность. Это те свойства, которые транзакции базы данных должны гарантировать своим пользователям достоверность даже в случае сбоя, ошибки, отказа оборудования и т.п. Без ACID или подобных контрактов разработчики приложений не могли бы сориентироваться, что является их обязанностью, а что обеспечивает база данных. Большинство реляционных транзакционных баз данных стараются быть ACID-совместимыми, но новые подходы, такие как движение NoSQL, породили множество баз данных без ACID-транзакций, потому что их дорого реализовывать.
Когда я только начинал работать в отрасли, наш технический руководитель спорил, является ли ACID устаревшей концепцией или нет. Справедливо сказать, что ACID считается свободным описанием, а не строгим стандартом реализации. Сегодня я считаю его в основном полезным, потому что он дает категорию проблем (и категорию возможных решений).
Не каждая база данных соответствует стандарту ACID, и среди баз данных, соответствующих стандарту ACID, ACID может интерпретироваться по-разному. Одной из причин, по которой ACID реализуется по-разному, является ряд компромиссов, связанных с реализацией возможностей ACID. Базы данных могут рекламировать себя как ACID, но все равно могут иметь различную интерпретацию в граничных случаях или в том, как они обрабатывают "маловероятные" события. Разработчики могут, по крайней мере, изучить на высоком уровне, как реализуются базы данных, чтобы иметь правильное представление о режимах отказа и компромиссах при проектировании.
Одним из известных споров является вопрос о том, насколько ACID является MongoDB даже после версии 4. MongoDB долгое время не имела поддержки журналирования, хотя по умолчанию она не фиксировала файлы данных на диск не чаще (каждые 60 секунд). Рассмотрим следующий сценарий, приложение делает две записи (w1 и w2). MongoDB смогла сохранить изменения для первой записи, но не смогла сделать это для w2, потому что произошел сбой из-за аппаратного сбоя.
 Иллюстрация потери данных при сбое MongoDB до записи на физический диск.
Иллюстрация потери данных при сбое MongoDB до записи на физический диск.
Фиксация на диск - дорогостоящий процесс, и, избегая фиксации, они заявляли о производительности при записи, жертвуя при этом долговечностью. На сегодняшний день MongoDB имеет журналирование, но грязные записи все еще могут повлиять на долговечность данных, поскольку по умолчанию они фиксируют журналы каждые 100 мс. Тот же сценарий все еще возможен для долговечности журналов и изменений, представленных в этих журналах, хотя риск значительно меньше.
Каждая база данных имеет различные возможности согласованности и изоляции.
Среди свойств ACID согласованность и изоляция имеют самый широкий спектр различных деталей реализации, поскольку спектр компромиссов шире. Согласованность и изоляция являются дорогостоящими возможностями. Они требуют координации и увеличивают количество конфликтов для поддержания согласованности данных. При необходимости горизонтального масштабирования между центрами обработки данных (особенно между различными географическими регионами) проблемы значительно усложняются. Обеспечить высокий уровень согласованности может быть крайне сложно, поскольку доступность снижается, а сетевые разделы происходят все чаще. Более общее объяснение этого явления см. в теореме CAP. Стоит также отметить, что приложения могут справиться с некоторой непоследовательностью, или программисты могут иметь достаточное представление о проблеме, чтобы добавить дополнительную логику в приложение, чтобы справиться с ней, не полагаясь в значительной степени на свою базу данных.
Базы данных часто предоставляют различные уровни изоляции, поэтому разработчики приложений могут выбрать наиболее экономически эффективный из них, основываясь на компромиссах. Более слабая изоляция может быть быстрее, но может привести к появлению гонок данных. Более сильная изоляция устраняет некоторые потенциальные гонки данных, но работает медленнее и может привести к возникновению противоречий, которые замедлят работу базы данных до такой степени, что это может привести к сбоям.
 Обзор существующих моделей параллелизма и связей между ними
Обзор существующих моделей параллелизма и связей между ними
Стандарт SQL определяет только четыре уровня изоляции, хотя теоретически и практически существует больше уровней. jepson.io предоставляет убедительный обзор существующих моделей параллелизма, если вам нужно дополнительное чтение. Например, Spanner от Google гарантирует внешнюю сериализуемость с синхронизацией часов, и хотя это более строгий уровень изоляции, он не определен в стандартных уровнях изоляции.
Уровни изоляции, упомянутые в стандарте SQL, следующие:
- Serializable (самый строгий, дорогой): Сериализуемое выполнение дает тот же эффект, что и последовательное выполнение этих транзакций. Последовательное выполнение - это такое выполнение, при котором каждая транзакция выполняется до завершения перед началом следующей транзакции. Одно замечание об уровне Serializable заключается в том, что он часто реализуется как "моментальная изоляция" (например, в Oracle) из-за различий в интерпретации, а "моментальная изоляция" не представлена в стандарте SQL.
- Повторяющиеся чтения: Незафиксированные чтения в текущей транзакции видны текущей транзакции, но изменения, сделанные другими транзакциями (например, вновь вставленные строки), не будут видны.
- Read committed: незафиксированные чтения не видны транзакциям. Видимы только зафиксированные записи, но фантомные чтения могут происходить. Если другая транзакция вставляет и фиксирует новые строки, текущая транзакция может увидеть их при запросе.
- Чтение без фиксации (наименее строгое, дешевое): Грязные чтения разрешены, транзакции могут видеть еще не зафиксированные изменения, сделанные другими транзакциями. На практике этот уровень может быть полезен для возврата приблизительных агрегатов, таких как запросы COUNT(*) к таблице.
Сериализуемый уровень обеспечивает наименьшие возможности для возникновения гонок данных, хотя является самым дорогим и вносит наибольшую напряженность в систему. Другие уровни изоляции дешевле, но увеличивают возможность возникновения гонок данных. Некоторые базы данных позволяют устанавливать свой уровень изоляции, некоторые базы данных имеют свое мнение по этому поводу и не обязательно поддерживают все из них.
Даже если базы данных рекламируют свою поддержку этих уровней изоляции, тщательное изучение их поведения может дать больше информации о том, что они делают на самом деле.
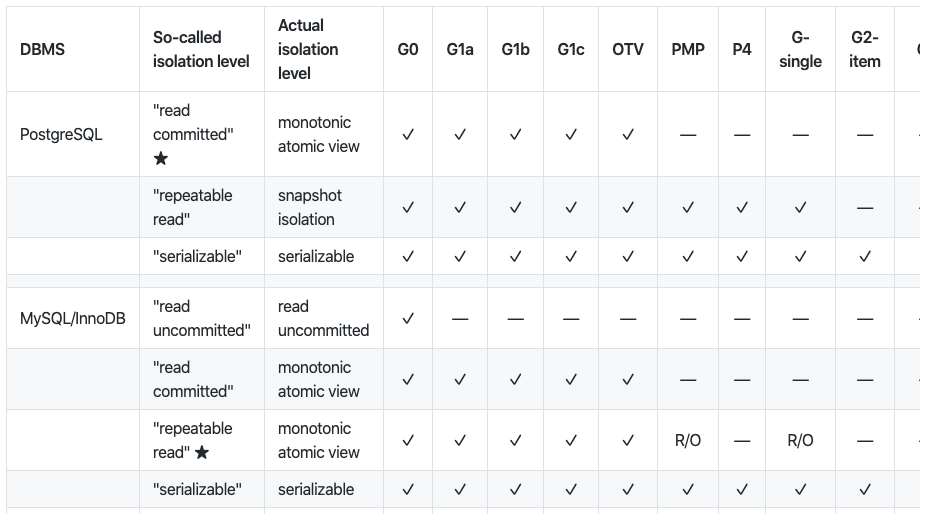 Обзор аномалий параллелизма при различных уровнях изоляции для каждой базы данных.
Обзор аномалий параллелизма при различных уровнях изоляции для каждой базы данных.
Отшельничество Мартина Клеппманна дает обзор различных аномалий параллелизма и того, способна ли база данных справиться с ними при определенном уровне изоляции. Исследование Клеппманна показывает, как уровни изоляции могут по-разному интерпретироваться разработчиками баз данных.
Оптимистическая блокировка - это вариант, когда вы не можете удерживать блокировку.
Блокировки могут быть очень дорогими не только потому, что они вносят больше противоречий в вашу базу данных, но они могут потребовать последовательных соединений от ваших серверов приложений к базе данных. Эксклюзивные блокировки могут быть более подвержены влиянию сетевых разделов и вызывать тупиковые ситуации, которые трудно определить и разрешить. В случаях, когда удерживать эксклюзивные блокировки нелегко, можно воспользоваться оптимистической блокировкой.
Оптимистическая блокировка - это метод, когда вы читаете строку, записываете номер версии, метку последнего изменения или контрольную сумму. Затем вы можете атомарно проверить, не изменилась ли версия, прежде чем изменить запись.
UPDATE products SET name = 'Telegraph receiver', version = 2 WHERE id = 1 AND version = 1
Обновление таблицы products повлияет на 0 строк, если ранее это строка была изменена другим обновлением. Если ранее никаких обновлений не было, то обновление затронет 1 строку, и мы можем сказать, что наше обновление прошло успешно.
Существуют и другие аномалии, кроме грязных чтений и потери данных.
Когда мы говорим о согласованности данных, мы в первую очередь уделяем много внимания возможным условиям гонки, которые могут привести к грязному чтению и потере данных. Но аномалии с данными не ограничиваются только ими.
Примером такого типа аномалий являются перекосы при записи. Перекосы при записи труднее выявить, потому что мы их активно не ищем. Перекосы при записи возникают не тогда, когда на записи происходят грязные чтения или потерянные данные, а когда нарушаются логические ограничения на данные.
Например, предположим, что приложение для мониторинга требует, чтобы один человек среди операторов постоянно находился на связи.
BEGIN tx1; BEGIN tx2; SELECT COUNT(*) FROM operators WHERE oncall = true; 0 SELECT COUNT(*) FROM operators WHERE oncall = TRUE; 0 UPDATE operators UPDATE operators SET oncall = TRUE SET oncall = TRUE WHERE userId = 4; WHERE userId = 2; COMMIT tx1; COMMIT tx2;
В приведенной выше ситуации перекос записи будет иметь место, если две транзакции успешно зафиксируются. Даже если не произошло грязного чтения или потери данных, целостность данных будет потеряна, поскольку два человека назначены дежурными.
Сериализуемая изоляция, проектирование схемы или ограничения базы данных могут помочь устранить перекос записи. Разработчики должны уметь выявлять такие аномалии во время разработки, чтобы избежать аномалий данных в производстве. Однако выявить перекосы записи в кодовых базах может быть крайне сложно. Особенно в больших системах, если разные команды отвечают за создание функций на основе одних и тех же таблиц, не разговаривая друг с другом и не изучая, как они обращаются к данным.
Мы с моей базой данных не всегда согласны по поводу упорядочивания.
Одной из основных возможностей баз данных являются гарантии упорядочения, но упорядочение может быть неожиданным для разработчика приложений. Базы данных видят транзакции в том порядке, в котором они их получают, а не в том, в котором их видят разработчики. Порядок выполнения транзакций трудно предсказать, особенно в многопользовательских параллельных системах.
Во время разработки, особенно при работе с неблокирующими библиотеками, плохой стиль и читабельность могут способствовать возникновению проблемы, когда пользователи думают, что транзакции выполняются последовательно, хотя они могут поступать в базу данных в любом порядке. Приведенная ниже программа создает впечатление, что T1 и T2 будут вызываться последовательно, но если эти функции неблокирующие и возвращаются сразу с обещанием, то порядок вызова будет зависеть от времени их поступления в базу данных.
result1 = T1() // results are actually promises
result2 = T2()
Если требуется атомарность (полная фиксация или прерывание всех операций) и последовательность имеет значение, операции в T1 и T2 должны выполняться в одной транзакции базы данных.
Шардинг на уровне приложения может жить вне приложения.
Шардинг - это способ горизонтального разделения базы данных. Хотя некоторые базы данных могут автоматически разбивать данные по горизонтали, некоторые не могут или не умеют этого делать. Когда архитекторы/разработчики данных могут предсказать, как будет осуществляться доступ к данным, они могут создать горизонтальные разделы на уровне пользователя вместо того, чтобы делегировать эту работу базе данных. Это называется шардингом на уровне приложения.
Название "шардинг на уровне приложений" часто создает неверное впечатление, что шардинг должен быть реализован в прикладных службах. Возможности шардинга могут быть реализованы как слой перед базой данных. В зависимости от роста данных и итераций схемы, требования к шардингу могут усложняться. Возможность итерации некоторых стратегий без необходимости развертывания серверов приложений может оказаться полезной.

Пример архитектуры, в которой серверы приложений отделены от службы шардинга.
Наличие шардинга в виде отдельной службы может расширить ваши возможности по итерации стратегий шардинга без необходимости развертывания приложений. Одним из таких примеров системы шардинга на уровне приложений является Vitess. Vitess обеспечивает горизонтальный шардинг для MySQL и позволяет клиентам подключаться к нему по протоколу MySQL, а сам шардинг распределяет данные по различным узлам MySQL, которые не знают друг о друге.
AUTOINCREMENT'ing может быть вредным.
AUTOINCREMENT'ing - это распространенный способ генерации первичных ключей. Нередко встречаются случаи, когда базы данных используются в качестве генераторов идентификаторов, и в базе данных есть таблицы, предназначенные для генерации идентификаторов. Есть несколько причин, по которым генерация первичных ключей с помощью автоинкремента может быть не идеальной:
- В распределенных системах баз данных автоинкрементирование является сложной проблемой. Для генерации идентификатора потребуется глобальная блокировка. Если вместо этого можно генерировать UUID, это не потребует никакого взаимодействия между узлами базы данных. Автоинкремент с блокировками может привести к возникновению противоречий и значительно снизить производительность при вставке в распределенных ситуациях. Некоторые базы данных, такие как MySQL, могут потребовать специфической конфигурации и большего внимания, чтобы все было правильно при репликации мастер-мастер. В конфигурации легко ошибиться, что может привести к сбоям при записи.
- В некоторых базах данных алгоритмы разделения основаны на первичных ключах. Последовательные идентификаторы могут вызвать непредсказуемые "горячие точки" и перегрузить одни разделы, в то время как другие останутся незанятыми.
- Самый быстрый способ доступа к строке в базе данных - по ее первичному ключу. Если у вас есть лучшие способы идентификации записей, последовательные идентификаторы могут сделать самый значимый столбец в таблицах бессмысленным значением. По возможности выбирайте глобально уникальный естественный первичный ключ (например, имя пользователя).
Пожалуйста, рассмотрите влияние автоинкрементных идентификаторов и UUID на индексирование, разделение и шардинг, прежде чем решить, что лучше для вас.
Несвежие данные могут быть полезны и без блокировки.
Многоверсионный контроль параллелизма (MVCC) позволяет реализовать многие из функций согласованности, о которых мы кратко говорили выше. Некоторые базы данных (например, Postgres, Spanner) используют MVCC, чтобы позволить каждой транзакции видеть снимок, более старую версию базы данных. Транзакции против моментальных снимков все еще могут быть сериализуемыми для обеспечения согласованности. При чтении из старого снимка вы читаете устаревшие данные.
Чтение немного устаревших данных может быть полезным, например, когда вы генерируете аналитику на основе ваших данных или вычисляете приблизительные агрегированные значения.
Первым преимуществом чтения устаревших данных будет задержка (особенно если ваша база данных распределена между различными географическими регионами). Вторым преимуществом базы данных MVCC является то, что она позволяет транзакциям, предназначенным только для чтения, быть свободными от блокировок. Это большое преимущество для приложений с интенсивным чтением, если можно смириться с неактуальными данными.
 Сервер приложений считывает устаревшие данные 5-секундной давности из локальной реплики, хотя последняя версия доступна на другом берегу Тихого океана.
Сервер приложений считывает устаревшие данные 5-секундной давности из локальной реплики, хотя последняя версия доступна на другом берегу Тихого океана.
Базы данных сметают старые версии автоматически, а в некоторых случаях они позволяют делать это по требованию. Например, Postgres позволяет пользователям проводить VACUUM по требованию, а также автоматически пылесосить раз в некоторое время, а Spanner запускает сборщик мусора, чтобы избавиться от версий старше часа.
Перекосы часов происходят между любыми источниками синхронизации.
Самый хорошо скрываемый секрет в вычислительной технике заключается в том, что все временные API лгут. Наши машины не могут точно знать текущее время. Все наши компьютеры содержат кварцевый кристалл, который вырабатывает сигнал для отсчета времени. Но кварцевые кристаллы не могут точно тикать и дрейфуют во времени либо быстрее, либо медленнее, чем реальные часы. Дрейф может составлять до 20 секунд в день. Время на наших компьютерах необходимо время от времени синхронизировать с реальным временем для обеспечения точности.
Для синхронизации используются серверы NTP, но сама синхронизация может задерживаться из-за сети. Если синхронизация с NTP-сервером в том же центре обработки данных может занять время, то синхронизация с общедоступным NTP-сервером может вызвать больший перекос.
Атомные часы и часы GPS являются лучшими источниками для определения текущего времени, но они дороги и требуют сложной настройки, поэтому их невозможно установить на каждой машине. Учитывая эти ограничения, в центрах обработки данных используется многоуровневый подход. Хотя атомные и/или GPS-часы обеспечивают точное время, их время транслируется на остальные машины через вторичные серверы. Это означает, что каждая машина будет отклоняться от реального текущего времени с некоторой величиной.
Это еще не все... Приложения и базы данных часто живут на разных машинах (если не в разных центрах). Не только узлы базы данных, распределенные на нескольких машинах, не смогут договориться о времени, часы сервера приложений и часы узла базы данных также не смогут договориться.
-
TrueTime от Google придерживается другого подхода. Большинство людей считают, что прогресс Google в области часов можно объяснить использованием атомных и GPS-часов, но это лишь часть истории. Вот что делает компания TrueTime:
-
TrueTime использует два разных источника: GPS и атомные часы. Эти часы имеют разные режимы сбоя, поэтому использование обоих источников повышает надежность.
TrueTime имеет нетрадиционный API. Он возвращает время в виде интервала. На самом деле время может быть в любом месте между нижней и верхней границей. Распределенная база данных Spanner компании Google может ждать до тех пор, пока не будет уверена, что текущее время находится за пределами определенного интервала. Этот метод добавляет некоторую задержку в систему, особенно когда неопределенность, объявленная мастерами, высока, но обеспечивает корректность даже в глобально распределенной ситуации.
 Компоненты Spanner используют TrueTime, где TT.now() возвращает интервал, поэтому Spanner может внедрять sleeps, чтобы убедиться, что текущее время прошло определенную временную метку.
Компоненты Spanner используют TrueTime, где TT.now() возвращает интервал, поэтому Spanner может внедрять sleeps, чтобы убедиться, что текущее время прошло определенную временную метку.
Если уверенность в текущем времени уменьшается, это означает, что операции Spanner могут занять больше времени. Вот почему, несмотря на то, что иметь точные часы невозможно, для производительности все же важно поддерживать высокий уровень уверенности.
Латентность имеет много значений.
Если спросить десять человек в одной комнате, что означает "задержка", все они могут ответить по-разному. В базах данных латентность часто называют "латентностью базы данных", но не той латентностью, которую воспринимает клиент. Клиент видит латентность, состоящую из латентности базы данных и сетевой латентности. Умение определить задержку клиента и базы данных очень важно при отладке нарастающих проблем. При сборе и отображении метрик всегда учитывайте наличие обоих показателей.
Оцените требования к производительности в расчете на одну транзакцию.
Иногда базы данных рекламируют свои характеристики производительности и ограничения в терминах пропускной способности и задержки при записи и чтении. Хотя это может дать высокоуровневый обзор основных блокирующих факторов, при оценке новой базы данных на предмет производительности, более комплексный подход заключается в оценке критических операций (на запрос и/или на транзакцию) отдельно. Примеры:
- Пропускная способность и задержка при вставке новой строки в таблицу X (с 50 М строк) с заданными ограничениями и заполнении строк в связанных таблицах.
Задержка при запросе друзей друзей пользователя, когда среднее число друзей составляет 500. - Задержка при извлечении 100 лучших записей для временной шкалы пользователя, когда пользователь подписан на 500 аккаунтов, которые имеют X записей в час.
- Оценка и эксперименты могут содержать такие критические случаи, пока вы не будете уверены, что база данных сможет удовлетворить ваши требования к производительности. Аналогичное правило также учитывает эту разбивку при сборе показателей задержки и установлении SLO.
Будьте осторожны с высокой кардинальностью при сборе метрик на операцию. Используйте журналы, равномерный сбор или распределенную трассировку, если вам нужны отладочные данные с высокой кардинальностью. Обзор методик отладки задержек см. в разделе Хотите отладить задержку?
Вложенные транзакции могут быть вредными.
Не каждая база данных поддерживает вложенные транзакции, но когда они поддерживаются, вложенные транзакции могут вызвать неожиданные ошибки программирования, которые не всегда легко определить, пока не станет ясно, что вы видите аномалии.
Если вы хотите избежать вложенных транзакций, клиентские библиотеки могут выполнять работу по обнаружению и предотвращению вложенных транзакций. Если вы не можете их избежать, вам нужно быть внимательным, чтобы избежать неожиданных ситуаций, когда совершенные транзакции случайно прерываются из-за дочерней транзакции.
Инкапсуляция транзакций на разных уровнях может способствовать возникновению удивительных случаев вложенных транзакций, и с точки зрения удобства чтения может быть трудно понять их замысел. Взгляните на следующую программу:
with newTransaction(): Accounts.create("609-543-222") with newTransaction(): Accounts.create("775-988-322") throw Rollback();
Каков будет результат приведенного выше кода? Откатит ли он обе транзакции или только внутреннюю? Что произойдет, если мы будем полагаться на несколько уровней библиотек, которые инкапсулируют от нас создание транзакций. Смогли бы мы выявить и улучшить такие случаи?
Представьте себе слой данных с несколькими операциями (например, newAccount), которые уже реализованы в собственных транзакциях. Что произойдет, если вы запустите их в бизнес-логике более высокого уровня, которая выполняется в собственной транзакции? Каковы будут характеристики изоляции и согласованности?
function newAccount(id string) { with newTransaction(): Accounts.create(id) }
Вместо того чтобы решать такие открытые вопросы, избегайте вложенных транзакций. Ваш уровень данных может по-прежнему реализовывать операции высокого уровня без создания собственных транзакций. Затем бизнес-логика может запускать транзакции, выполнять операции в транзакции, фиксировать или прерывать их.
function newAccount(id string) { Accounts.create(id) } // In main application: with newTransaction(): // Read some data from database for configuration. // Generate an ID from the ID service. Accounts.create(id) Uploads.create(id) // create upload queue for the user.
Транзакции не должны поддерживать состояние приложения.
Разработчики приложений могут захотеть использовать состояние приложения в транзакциях для обновления определенных значений или изменения параметров запроса. При этом необходимо учесть одну важную вещь - правильную область применения. Клиенты часто повторяют транзакции при возникновении сетевых проблем. Если транзакция полагается на состояние, которое мутировало в другом месте, она может выбрать неправильное значение в зависимости от вероятности гонок данных в проблеме. Транзакции должны быть осторожны с внутриприкладными гонками данных.
var seq int64 with newTransaction(): newSeq := atomic.Increment(&seq) Entries.query(newSeq) // Other operations...
Приведенная выше транзакция будет увеличивать номер последовательности каждый раз, когда она выполняется, независимо от конечного результата. Если фиксация не удалась из-за сети, при второй повторной попытке она выполнит запрос с другим порядковым номером.
Планировщики запросов могут рассказать о базах данных.
Планировщики запросов определяют, как ваш запрос будет выполняться в базе данных. Они также анализируют запросы и оптимизируют их перед выполнением. Планировщики могут только предоставить некоторые возможные оценки на основе имеющихся у него сигналов. Как найти результаты для следующего запроса:
SELECT * FROM articles where author = "rakyll" order by title;
Существует два способа получения результатов:
- Полное сканирование таблицы: Мы можем просмотреть каждую запись в таблице и вернуть статьи, в которых имя автора совпадает, затем упорядочить.
- Индексное сканирование: Мы можем использовать индекс для поиска совпадающих идентификаторов, извлечь эти строки и затем упорядочить.
Роль планировщика запросов заключается в том, чтобы определить, какая стратегия является наилучшим вариантом. Планировщики запросов имеют ограниченные сигналы о том, что они могут предсказать и могут привести к неправильным решениям. DBA или разработчики могут использовать их для диагностики и точной настройки плохо работающих запросов. Новые версии баз данных могут подстраивать планировщики запросов, и их самодиагностика может помочь вам при обновлении базы данных, если в новой версии возникнут проблемы с производительностью. Такие отчеты, как журналы медленных запросов, проблемы задержки или статистика времени выполнения, могут быть полезны для определения запросов, которые необходимо оптимизировать.
Некоторые метрики, предоставляемые планировщиком запросов, могут быть шумными, особенно при оценке задержки или процессорного времени. В качестве дополнения к планировщикам запросов, инструменты трассировки и пути выполнения могут быть более полезными для диагностики этих проблем, хотя не каждая база данных предоставляет такие инструменты.
Онлайн-миграции сложны, но возможны.
Миграция в режиме онлайн, в реальном времени или в реальном времени означает миграцию из одной базы данных в другую без простоев и ущерба для корректности данных. Живые миграции проще, если вы мигрируете на ту же базу данных/двигатель, но могут стать более сложными при миграции на новую базу данных с другими характеристиками производительности и требованиями к схеме.
Существуют различные модели, когда речь идет об онлайн-миграции, вот одна из них:
- Начните выполнять двойную запись в обе базы данных. На этом этапе новая база данных не будет иметь всех данных, но начнет видеть новые. Как только вы будете уверены в этом шаге, можно переходить ко второму.
- Начните включать путь чтения для использования обеих баз данных.
- Используйте новую базу данных в основном для чтения и записи.
- Прекратите запись в старую базу данных, но продолжайте читать из старой базы данных. На этом этапе новая база данных все еще не содержит всех новых данных, и вам может потребоваться возврат к старой базе данных для старых записей.
- На этом этапе старая база данных доступна только для чтения. Заполните новую базу данных недостающими данными из старой базы данных. После завершения миграции все пути чтения и записи могут использовать новую базу данных, а старая база данных может быть удалена из вашей системы.
Если вам нужно больше примеров, посмотрите исчерпывающую статью Stripe об их стратегии миграции, которая следует этой модели.
Значительный рост базы данных вносит непредсказуемость.
Рост базы данных заставляет вас столкнуться с непредсказуемыми проблемами масштабирования. Чем больше мы знаем о внутреннем устройстве наших баз данных, тем меньше мы можем предсказать, как они могут масштабироваться, но есть вещи, которые мы не можем предсказать.
По мере роста предыдущие предположения или ожидания относительно объема данных и требований к пропускной способности сети могут устареть. Именно тогда происходит переписывание больших схем, масштабные операционные улучшения, проблемы с пропускной способностью, пересмотр развертывания или миграция на другие базы данных, чтобы избежать сбоев.
Не думайте, что знание многого о внутреннем устройстве вашей текущей базы данных - это единственное, что вам нужно, масштабирование приведет к появлению новых неизвестных. Непредсказуемые горячие точки, неравномерное распределение данных, неожиданные проблемы с емкостью и оборудованием, постоянно растущий трафик и новые разделы сети заставят вас пересмотреть вашу базу данных, вашу модель данных, вашу модель развертывания и размер вашего развертывания.